你好。我有这个数据库:http ://sqlfiddle.com/#!9/9554b 。第一张表负责显示酒店中存在的房间,第二张表 - 用于显示酒店中的现有预订。我试着想象一下:
 sql 代码负责数字的放置/分布顺序。它获取新的入住和退房日期,将它们与主表进行比较,并检查这些日期是否有空房。他将为新装甲分配第一个可用编号。一切都是合乎逻辑的。从这里开始出现这种数字的“混乱”分布。这里其实就是发号的select请求。
sql 代码负责数字的放置/分布顺序。它获取新的入住和退房日期,将它们与主表进行比较,并检查这些日期是否有空房。他将为新装甲分配第一个可用编号。一切都是合乎逻辑的。从这里开始出现这种数字的“混乱”分布。这里其实就是发号的select请求。
SET @start = '2016-12-12'; -- Новая дата заезда
SET @end = '2016-12-20'; -- Новая дата выезда
SELECT a.nomer
FROM allnomer a
LEFT JOIN main m
ON a.nomer = m.numbernomer
AND DATEDIFF(m.datestart, @end) * DATEDIFF(m.dateend, @start) <= 0
WHERE a.type = 'lux' AND m.numbernomer IS NULL
LIMIT 1
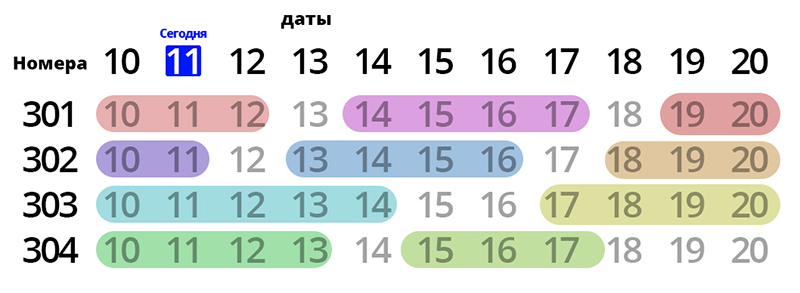
但我有一个问题。事实上,12日、13日、14日……20日,没有人住酒店。这些是免费的日子。它们是由于我的脚本分配日期而形成的。但是,如果 12 日到 20 日的预订在 11 日到达,那么脚本将拒绝它(返回 null),因为入住/退房日期重叠。这是意料之中的,但我想解决这个问题。如果您重新分配预订,那么一切都会水到渠成,12 到 20 的号码将会打开。
 我没有碰现有的盔甲,我只移动了未来的盔甲。我想知道重新分配/碎片整理的这项工作有多真实,以及如何实现它(也许已经有类似的东西,或者我的案例有这样的 sql 查询)?
我没有碰现有的盔甲,我只移动了未来的盔甲。我想知道重新分配/碎片整理的这项工作有多真实,以及如何实现它(也许已经有类似的东西,或者我的案例有这样的 sql 查询)?
从变量魔法的范畴优化查询。为更正确的数据库结构而设计,其中表
main中没有字段,namenomer因为它是从表中复制的allnomer,这违反了第二范式。该查询适用于您的数据库结构,并且可以减少更多,因为数字类型将直接从中获取main(但我不建议这样做,但我建议规范化数据库结构)。select subquery test at sqlfiddle.com(结果第一列是reserve record要设置的新编号,后面是reserve record的所有字段,包括旧编号。结果没有number=302 的记录,因为这个数字经过优化,结果是从 12 到 20 是免费的,并且没有分配给它一个单独的储备)。
工作原理:最深的子查询获取所有数字的列表,其中包含
@today今天有效储备的最后日期(变量)。如果此时房间空闲,则最后入住日期为昨天。此类所有编号中日期较晚的所有现有储备都粘在每个编号上。但实际上,他们的数据在工作中并没有用到,他们只需要生成一些已知足以模拟递归的记录。收到的记录按本次储备结束日期倒序排列。那些。第一个处理的数字将是 304,因为 他目前的储备在 13 日结束。对于每条记录,我们试图找到这样一条在查询中还没有遇到过(它不在变量中
@used)并且其开始日期最接近当前处理日期的保留记录。如果找到记录(@cidNOT NULL),那么我们将其结束日期作为下一个工作日期。这样,在下一条记录中,将找到开头最接近当前记录的一条记录。当当前号码处理结束(新号码不等于旧号码@cnum),工作日期重置为新号码的发布日期,我们寻找下一个储备链。PS 当然,存储过程可以做得更简单,更容易理解,同时保持一般原则。但是我有兴趣通过一个请求来完成它,尤其是在看起来不可能的情况下。
感谢您提出有趣的问题。
我尝试在 MS SQL 中实现该算法,并且在大多数地方都忽略了按数字类型过滤,我希望你可以将其转换为 MySQL 代码并在必要时添加类型条件 - 这应该很容易。
该算法的主要意义是重置开始时间大于当前日期的所有预订的编号,之后我们一次一个地重新分配编号,将它们尽可能密集地分配到已占用的日期。
结构和内容 - 来自 sqlfiddle 上的初始帖子。